In the past year or two, the term “data loss prevention” (DLP) has been overused by security vendors trying to make their products sound useful for solving the pervasive problem of data breaches. This has led to the situation where it can be difficult to tell which technologies deserve to be called “DLP” and which do not. To help clarify things, let’s look at what DLP technology is, how it works, and what it can and cannot do.
The term “data loss prevention” describes technology that automates the identification and protection of sensitive data. A DLP system has components that implement three functions: Management, Identification and Protection. The Management component is where an administrator creates and manages policies that the DLP system implements and generates any reports that are needed. The Identification component finds the sensitive data that the system’s policies define. The Protection component safeguards the sensitive data that the Identification component finds. Figure 1 shows the relationship between these three components. Each of these components has its own set of challenges, and we’ll look at each of these in turn.
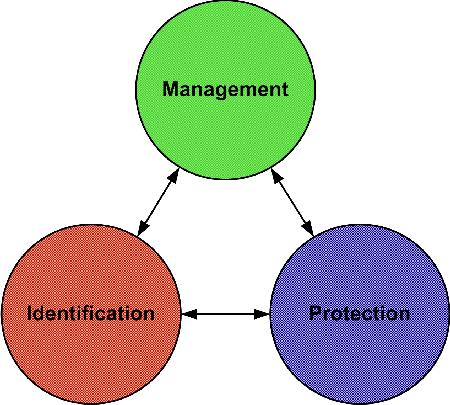
Figure 1. The functional components of a DLP system.
Automating the protection of sensitive data is important because even people with the best of intentions make mistakes. The 2008 edition of CompTIA’s Trends in Information Security report estimated that 30 percent of serious data breaches are caused by human errors, another 30 percent are caused by a hacker taking advantage of a human error, and only 40 percent are caused by a hacker actively overcoming flaws in technology. These numbers are quite a bit different than they were five years ago. The 2003 edition of the same report estimated that only 8 percent of serious data breaches did not involve some sort of human error.
People are getting better at protecting sensitive data, but they still not very good at it. It is still the case that most serious data breaches are caused by a failure of people instead of a failure of technology. Because of this, automating the process of protecting data will give much better results that just relying on error-prone people, and that is exactly where DLP technology promises to be able to make a difference.
Management
A DLP system’s policy defines what type of data is considered sensitive, what actions are allowed with sensitive data, and how to protect sensitive data. Suppose that we want to stop unencrypted Social Security numbers from being sent to external email addresses. This relatively simple goal may actually be difficult to implement in a comprehensive way, which means that it can be difficult to carefully create a policy that describes this goal. Consider the examples listed in Table 1. Each of these might or might not contain a Social Security number. The number 123456789 could be a Social Security number, for example, or it could be a telephone number for someone outside the US. A policy designed to stop unencrypted Social Security numbers from being sent to external email addresses needs to be able to define which of these should be identified as containing a Social Security number by the Identification components of the DLP system and which ones should not.
| Scenario |
| Email contains “123-45-6789” |
| Email contains “123456789” |
| Email has an attached spreadsheet that contains “123456789” |
| Email contains “123-456-789” |
| Email contains the URL “http://www.binhminhitc.com/books/123456789/” |
| Email contains source code that implements the logic print(123456789) |
| Email has an attached executable program that implements the logic print(123456789) |
Table 1. Examples that may or may not contain a Social Security number.
The policy of a DLP system also tells what action the Protection component of the system needs to take when the Identification component finds sensitive data. In the case of finding an unencrypted Social Security number, the Protection component might encrypt the message and send the encrypted message to the message’s recipients. Or it might notify the sender that they’ve violated the system’s data protection policy and that they’ll need to encrypt their message for it to be sent.
The capabilities of the Management component are limited by the thoroughness of the component, or how many different formats of data it can define rules for. Each particular file format, for example, encodes information in a different way. A DLP system needs to be able to understand the format of the data to search it for sensitive information. A Social Security number that is in a compressed text file, for example, will be encoded in a different way than the same number that is stored in a spreadsheet. In general, the more data formats that a DLP system can understand, the more thorough it is, and this usually means that it has a better chance of finding and protecting sensitive information.
Be careful of vendor claims, though. If a vendor claims that its DLP technology can identify many different kinds of file formats, that is not enough to let its technology identify sensitive information in all of those file types. What is important is how thorough a job the technology can do of finding sensitive data. To do this, it needs to understand the contents of many different types of files as well as many different networking protocols. That is a more appropriate way to measure the thoroughness of a DLP system than the number of types of files it can simply identify.
The capabilities of the tools that administrators use to define the policies that the Identification components use are also important. To be considered a DLP technology, these rules should be able to include more than just looking for keywords. State-of-the-art DLP technologies use more advanced techniques like regular expressions and statistical pattern matching to identify sensitive information. The capability to do a more thorough job of finding sensitive data requires the ability to define more detailed and complicated policies, so a sophisticated Management component is a necessary part of more advanced DLP technology.
Identification
The Identification component of a DLP system uses the policy that the Management component defines to find sensitive information. In all but the simplest cases, this means that the Identification component will be making a statistical test and using the result of that test to decide if it has found sensitive information. Because Identification components use statistical tests, they can never make decisions correctly all of the time.
All statistical tests have a chance of both false positives and false negatives. A false positive happens when data that is not sensitive data is mistakenly identified as sensitive data. No sensitive data is unnecessarily exposed if a false positive happens, but there is a price paid for the inaccurate decision in terms of the time and effort wasted by people, particularly if they need to find a way to work around the false match. A false negative happens when sensitive data is mistakenly identified as non-sensitive data. In the case of a false negative, sensitive data ends up unprotected, which may result in its loss or compromise.
A property of any statistical testing is that for a particular technology it is impossible to reduce both false positives and false negatives at the same time. This means that if the parameters that an Identification component of a DLP system uses are changed to decrease the false positive rate, the false negative rate must increase, or if the false negative rate is decreased, then the false positive rate must increase. This is a limitation imposed by the nature of statistical testing and not one particular to DLP technology, and the same limitation exists in other security technologies that perform statistical tests.
The best-known of these technologies is probably intrusion detection, which also involves the same tradeoff between false positives and false negatives. This means that if you are a security manager who is trying to understand the possible performance of a DLP system, the administrator of your intrusion detection system is probably a good source of information about the impact of false positives and false negatives on both system performance and security.
Protection
Once an Identification component of a DLP system decides that it has found sensitive data, the Protection components of the system takes whatever action its policy requires. Blocking and encryption are the two most common of these actions.
If a user is copying sensitive data to a USB drive, for example, the Protection component of a DLP system might block the transfer and not let the user copy the data to the USB drive. In other cases, the Protection component might encrypt the sensitive data in such a way that only authorized users can decrypt it. If a user is saving a file that contains sensitive data, the Protection component might encrypt the file before it is saved.
Blocking users’ actions usually does not cause significant technical problems, although it can increase the number of help desk calls. Most users who end up being blocked by a DLP system aren’t doing anything malicious; they’re just trying to do their jobs. They will often need help understanding how to work within the limitations that a DLP system will create for them, and this can increase the number of support calls that help desks receive.
Using encryption to protect sensitive data, on the other hand, can cause significant technical problems, both due to the problems associated with key management and the problems that many systems have processing encrypted data.
A cryptographic key is much like the combination to a safe. If you have the combination, it is easy to open a safe, but it is hard to open one without the combination. Similarly, if you have the right key, decrypting encrypted data is easy, but it is impractical without this key. But if you are careless with the combination to your safe, someone else can easily find it, and once they have it, the protection provided by the safe is compromised. Similarly, the cryptographic keys that you use to encrypt data need to be handled carefully. If you are careless with them the protection provided by cryptography can be essentially eliminated. Key management covers all the details of how to handle keys carefully enough to ensure that this does not happen. It ensures that you do not do the cryptographic equivalent of writing the combination to your safe on a Post-it note and sticking it to the wall next to your desk.
One obvious problem that DLP technology can cause that is related to key management is that of data recovery. If the key needed to decrypt data is not available for some reason, then protecting data by encrypting it acts just like cryptographically shredding the data. To avoid this problem, any cryptographic keys that a DLP system uses need to be highly available. This can be expensive, and it can easily turn into a large cost that DLP users do not expect and plan for.
The current state of the art in key management technology also has not reached the point where it is easy to request and download keys across the Internet. This means that if a DLP system finds sensitive data and encrypts it, it may be either difficult or impossible to decrypt the protected data if it is moved outside the network where it was originally encrypted. If the data is stored on a backup tape and shipped to an off-site facility for storage, for example, it may not be possible to decrypt the protected data off-site because of the inability to get the necessary decryption keys.
Being able to decrypt data when it is needed is just as important as being able to protect it. So if you plan to use DLP technology to encrypt data, you should carefully consider how the data can be decrypted when it is needed in the future and make sure that the key management technology that your DLP solution uses can support the way that you need to use it.
Another potential problem caused by DLP technologies is that some existing systems are unable to handle encrypted data. Encrypting data typically changes both the length and the format of the data. So if you encrypt a nine-digit Social Security number, the encrypted value is both no longer just digits and is longer than nine characters. In many computing environments, there is at least one system that will be unable to handle encrypted data, and there is often no way to find out which systems will have this problem other than by extensive testing.
One possible solution to this problem is to use one of the newer format-preserving encryption algorithms. These are not actually a new encryption algorithm, but instead are a new way to use an existing algorithm that inherits all of the security of the original algorithm. The so-called Feistel Finite Set Encryption Mode (FFSEM) that NIST has accepted for consideration as an approved mode of AES is an example of this technology. FFSEM uses the existing AES encryption algorithm in a way that both preserves the format of the unencrypted data while keeping all of the strength of the AES algorithm, and using it to encrypt sensitive data both protects the data and makes interoperability with existing systems possible.
Network vs. Endpoint DLP
There are two places where DLP technology can be used to protect data: in a network or at an endpoint. If the technology operates in a network, it operates as shown in Figure 2, where the identification and protection of sensitive data is performed on data as it moves through the network. This is the most common way for enterprises to start deploying DLP technology, typically first using the technology to stop data loss over email or Webmail, and then extending its use to other applications.
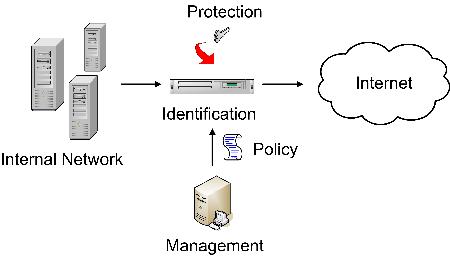
Figure 2. Network-based DLP.
An alternative to network-based DLP is endpoint-based DLP. This operates on a server or workstation and implements the DLP system’s policy there, as shown in Figure 3. This approach requires extending the DLP system to all of the workstations and servers in an enterprise, and this can create all of the support and maintenance challenges that any other widely-deployed enterprise software can cause.
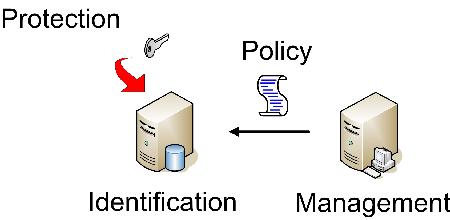
Figure 3. Endpoint-based DLP.
Endpoint-based DLP will typically find and protect more sensitive data than a network-based DLP solution will. An endpoint-based solution can monitor the transfer of data to portable devices, for example, while a network-based solution cannot. This additional capability comes with a price, both in terms of complexity and cost, which probably explains why endpoint-based DLP systems have not yet been deployed as widely as network-based DLP systems have.
DLP vendors often add a third type of technology to this mix, and that is what they call “discovery” technology. DLP discovery technology is very similar to endpoint-based technology, but it does not only look for sensitive data when it is triggered by particular events. While an endpoint DLP technology might look for sensitive data when certain events occur, like data is transferred to portable storage or a file is saved, discovery technology tries to find all sensitive information in stored data. To do this, it actively searches stored data and protects sensitive data that it finds.
DLP discovery technology adds another level of protection beyond that provided by endpoint-based technology. While endpoint and network DLP technologies identify and protect sensitive data only when certain events happen, discovery technology can potentially protect all sensitive data, even before these events occur. If discovery technology has found and encrypted all Social Security numbers in an entire enterprise computing environment, for example, then this information will keep its protection if it is sent over a network or transferred to a portable device.
Summary
DLP technology promises to greatly reduce the amount of data that is lost in data breaches, and leading DLP vendors can provide solutions that do a reasonably good job of finding and protecting the types of data that common data security, privacy laws and regulations address.
Network-based DLP technologies are a less expensive way to protect sensitive data, but they typically provide less protection than endpoint-based or discovery DLP technologies do. The decision of which technology or technologies to use is complicated and needs to involve many factors, including at least the nature of the laws and regulations that define how sensitive data needs to be protected and risk management strategy of the business considering deploying DLP technology.
Any DLP technology that protects sensitive data by encrypting it can cause unforeseen problems with key management. If you are considering doing this, be sure to ask DLP vendors about their key management technology and how easily it will integrate into your existing network. Doing this in the early stages of evaluating DLP technology can save you significant time and effort if you end up deploying and supporting DLP in your business.
Source: Luther Martin & infosectoday.com
